将原始的样本——标注,分割成可训练的数据集。最后生成的文档样式如下:

并进行数据分配:dev:test:train=12:2:1来生成序列化的数据集。
程序设计的思想:
前期准备:
一、对于一个崭新的领域我们需要一个标注的标准文档——这个一般需要领域里的专业人员来完成。例如医学领域:

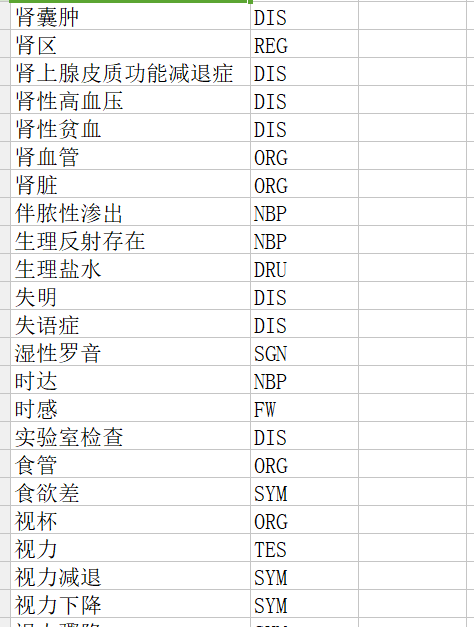
二、有了这个标准的标注细节文档,还要有对应的词典——一般通过网络上的爬取,自己来准备。样式如下:
有了以上两个条件针对我们的领域数据我们就可以处理了。
思路——这里利用词典进行命名实体的标注为后期的模型训练准备数据集:
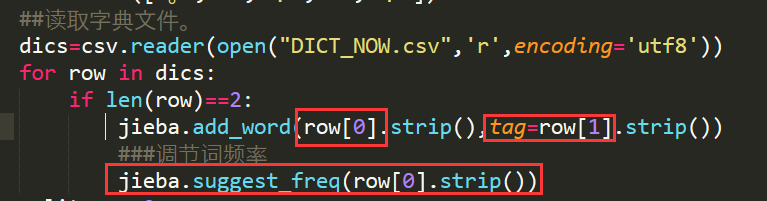
第一步:加载词典并调整词频。
第二步:将语料一篇一篇的读进来,并统计总共多少语料,——便于后期train、test、dev数据集的分配。
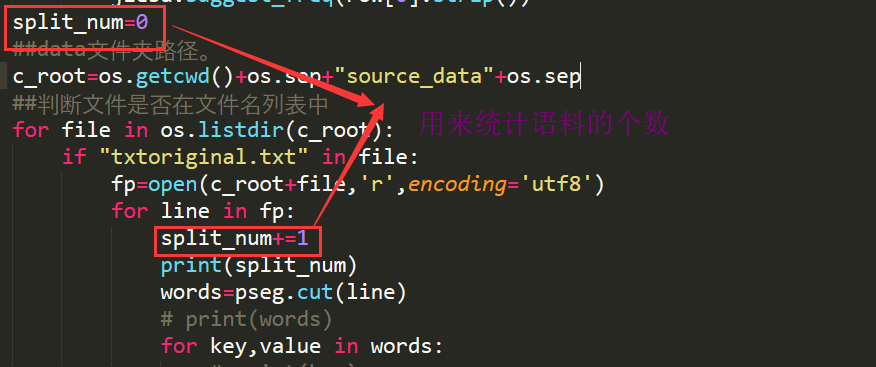
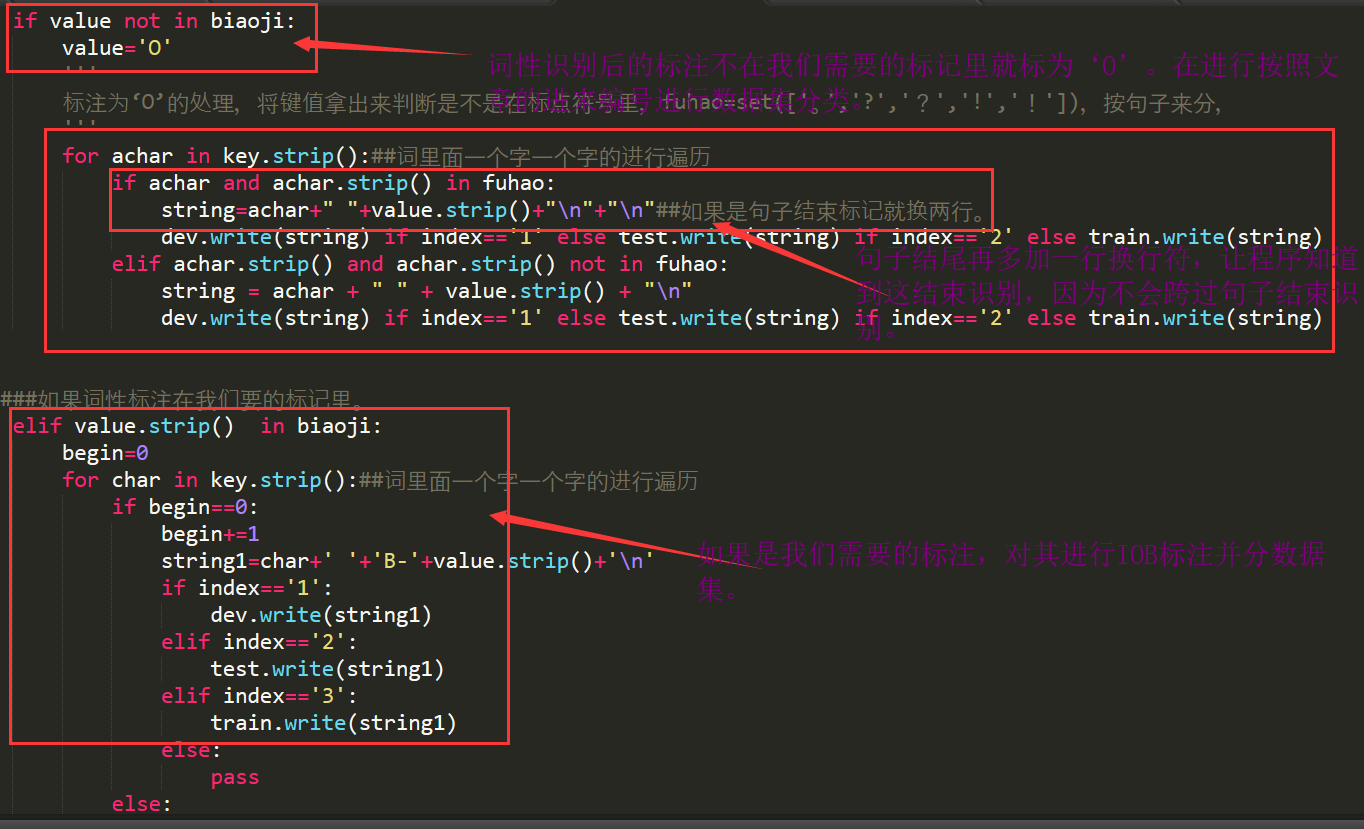
第三步:利用加载了领域词典和词频调节的工具进行词性识别。

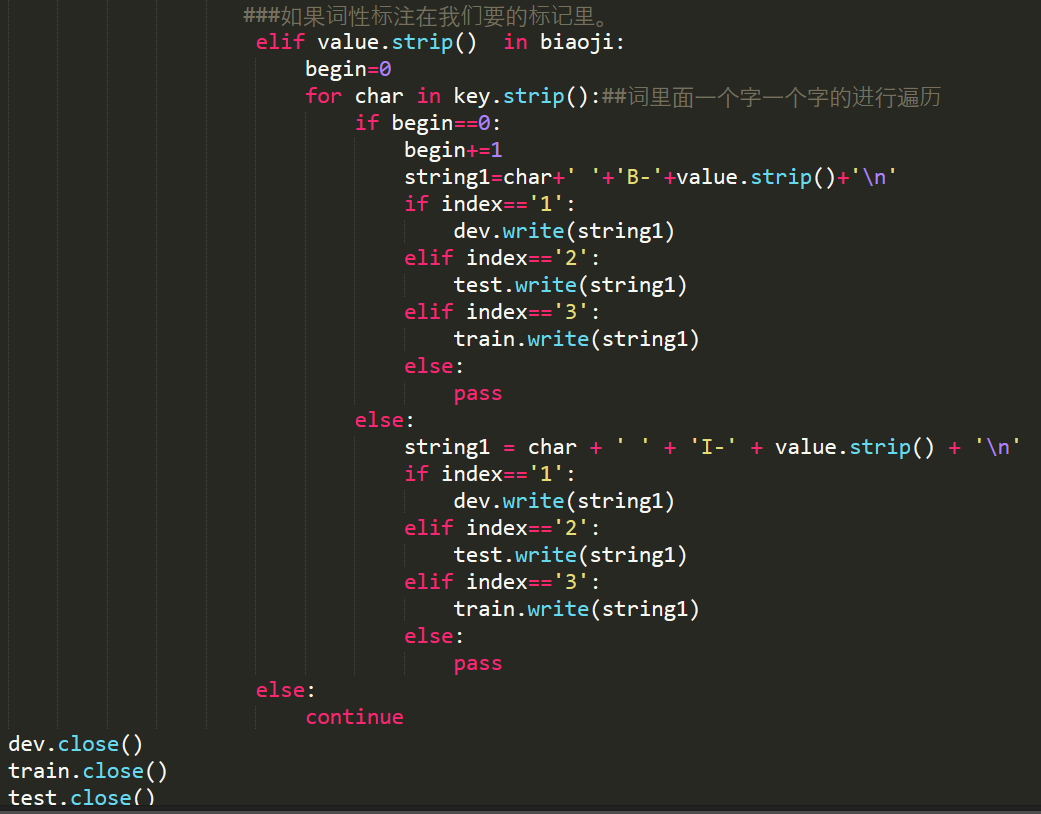
第四步:对词性识别后的结果进行标注处理。

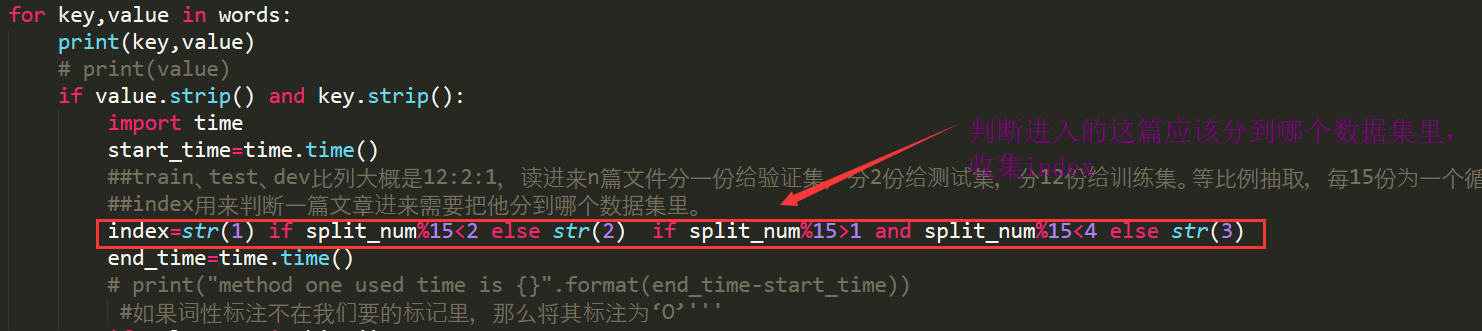

第五步:标注思想。