
CRF运用较多场景:
1) 基于字标注的分词
2) 基于词或字标注的主题提取(人名、地名、机构名、品牌、商品等实体识别)
CRF原理:如何轻松愉快的理解条件随机场(CRF)?
链接:http://www.jianshu.com/p/55755fc649b1
实操流程:图片引用自别处。(本文的例子是一个命名实体识别)
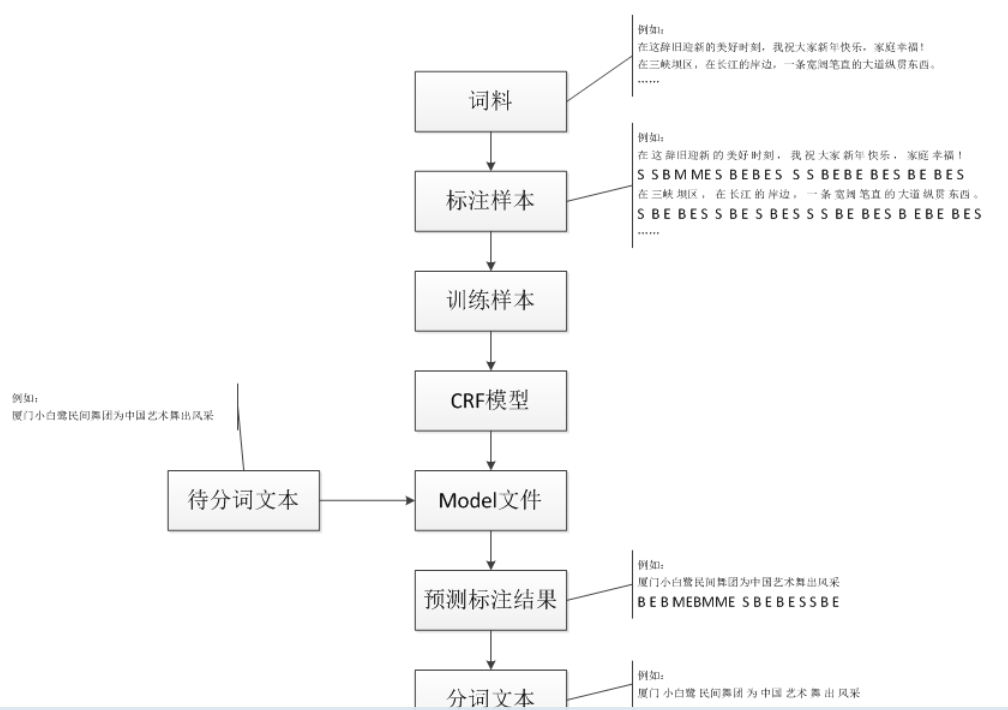
实际操作:
第一步:将文本以‘【】’人工对实体进行标注。
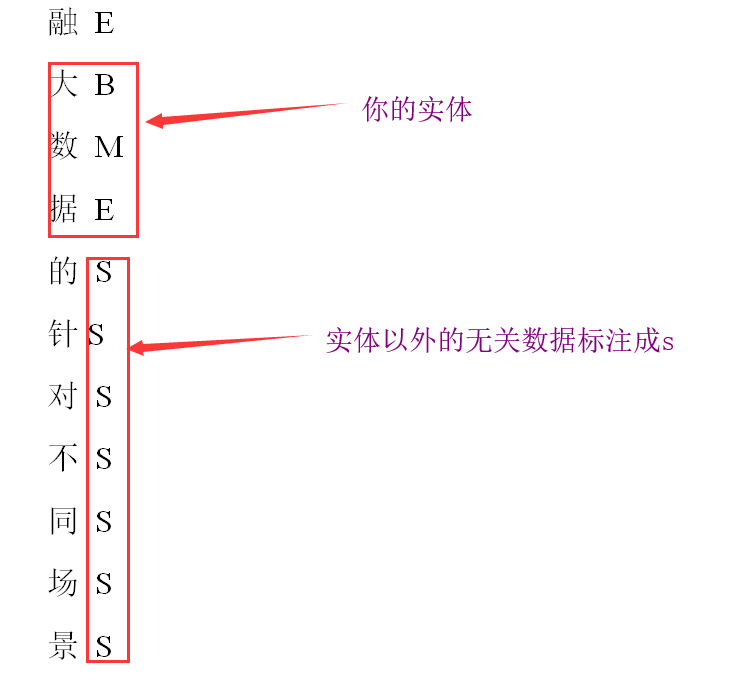
1、负责【互联网金融】【大数据】的针对不同场景的获
第二步:写序列标注程序。标注成如下样式:
注意:文件编码格式保存成gbk,我的保存成utf8最后模型训练好后,测试时出现了繁体字。
第三步:将标注好的数据分成训练数据(train.txt)和测试数据(test.txt),比列8:2.

第四步:下载CRF(上网搜下)
训练模型:

第五步:训练模型
.\crf_learn.exe template train.txt model01
第六步:测试
.\crf_test.exe -m model01 test.txt >>result.txt
第七步:模型效果评估:
下一篇中介绍
第八步:拿没有标注的语料进行标注-这里当我们的模型训练好时,评估结果也很好,下面我们就应该运用模型来实际干活了.
将待处理的文本放入train文件夹,并执行: .\crf_test.exe -m model01 test1.txt >>result123.txt
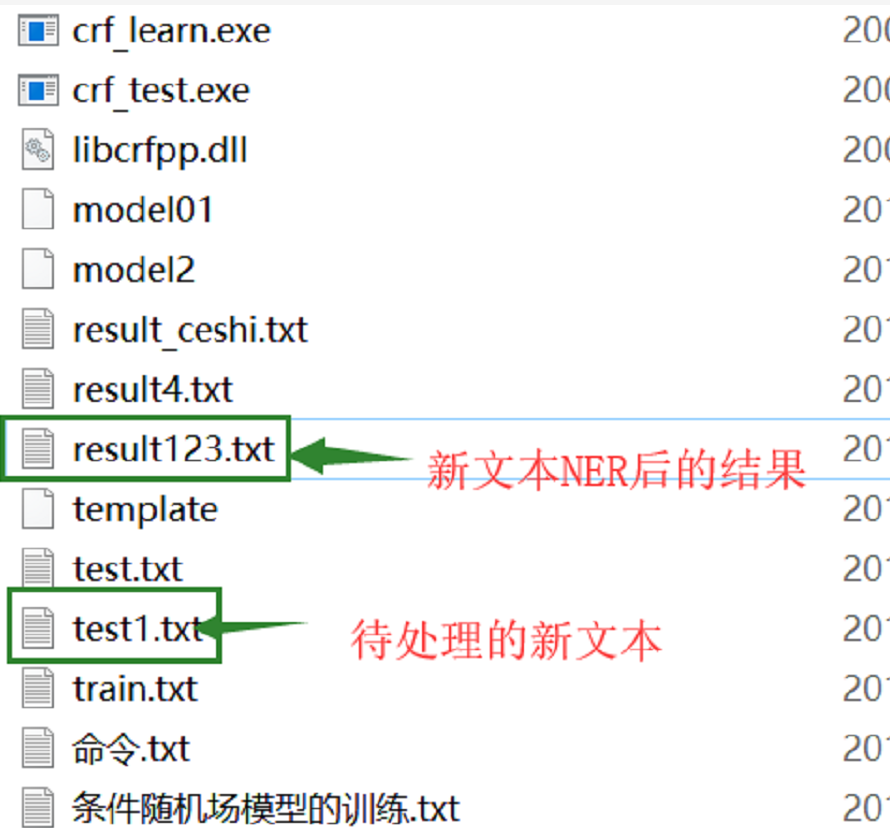

运用上述训练好的模型对新的样本test1.txt进行序列标注结果(也就是实体抽取):
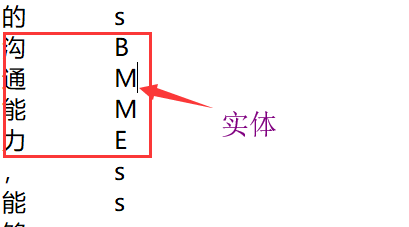
########################################################
改进:
在处理多个.txt文本处理时,我们需要运用到批处理-因为一篇一篇手写处理(太慢了)。下一篇中介绍如何批处理。
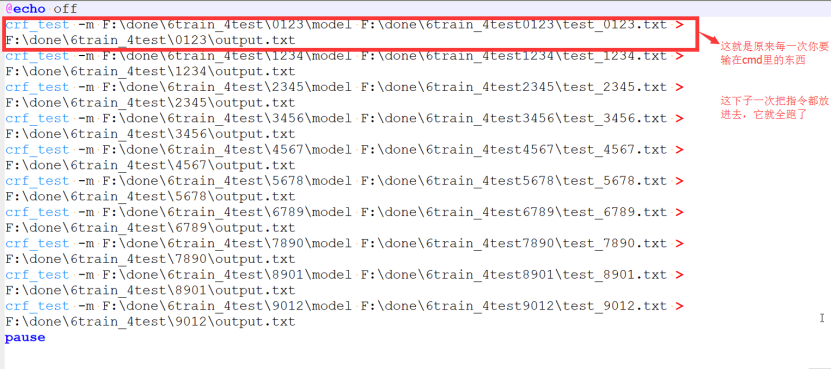
写一个txt文件,里面的内容写成和上图类似的,这个图片中开头和结尾不需要改,他们中间的换成你的指令(你可以写一段代码生成这么多长得差不多的语句,这个大家肯定能够写出来)。然后把你的txt后缀改成.bat,把这个bat文件放在你的crf++tools里,双击这个.bat文件,会弹出cmd的黑色框,cmd就自己跑起来了。
最后补充点知识语料如何分配:
语料中数据集的分配:师妹的手稿-感谢她!( )
)
