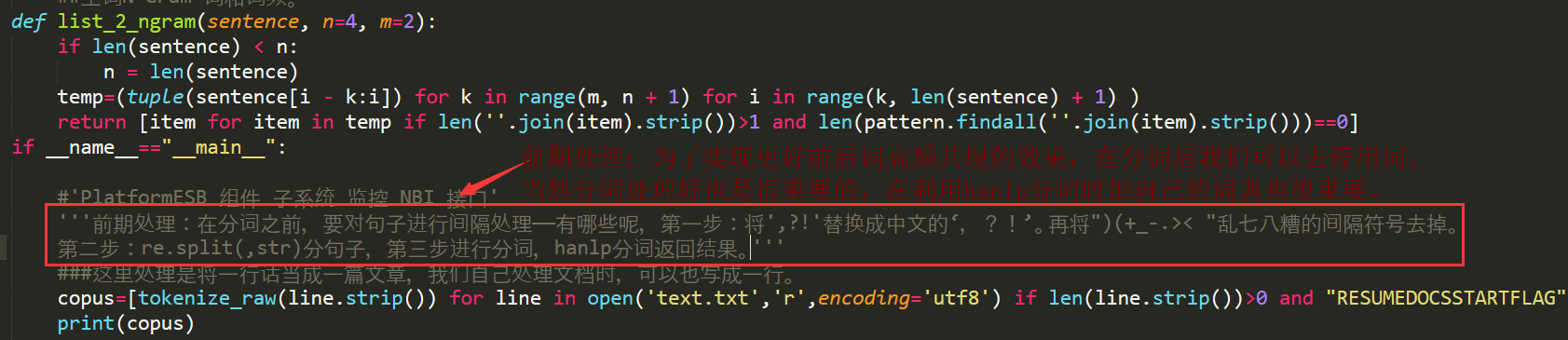
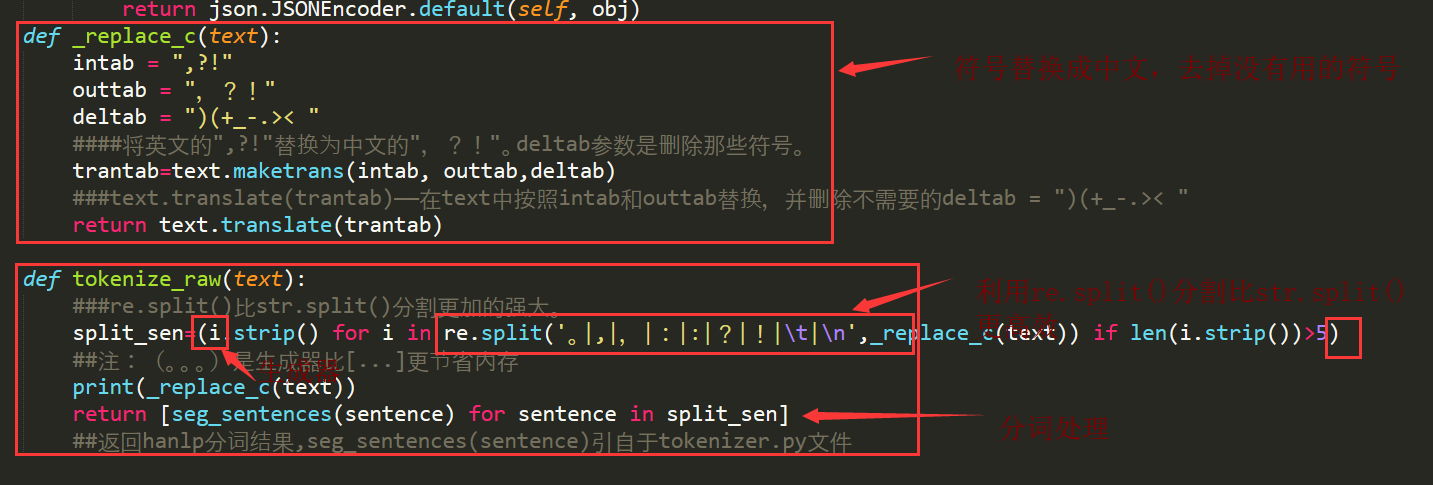
N-Gram的最根本是数学思想就是条件概率。结合上一篇的N-Gram,我们会了解到它的背后原理,利用这个原理,可以去计算哪些词或者字在语料中高频的连续出现在一起。
实际应用:我们可以挖掘出病历文本中某些疾病的几个症状通常同时出现,以及所用药物同时出现。用于病历文本的知识挖掘。
基于TF-IDF挖掘符合语言规范的N-Gram-即挖掘哪些词同时的高频出现在一起,哪些字同时的高频的出现在一起(注先去停用词)——停用词的去除方法可以参考《去噪音数据(停用词、形容词、动词等)-信息提取(利用hanlp词性识别去噪音的方法)》这篇文章或者自己写一个函数利用停用词的词典去除一部分噪音。
这里的Tf-IDF我们直接使用的sklearn中的TF-IDF。自己手写TF-IDF在后续文章中也会有介绍-应用案例实现关键词提取。
N-Gram:



##########################################################################################
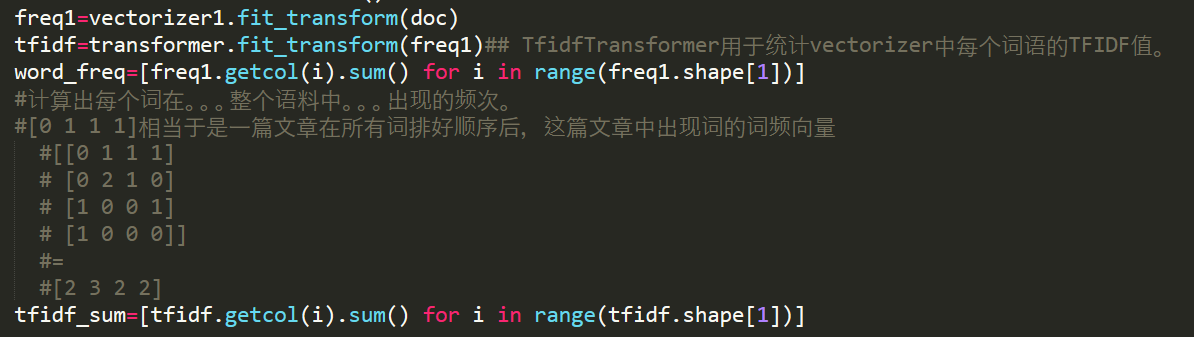
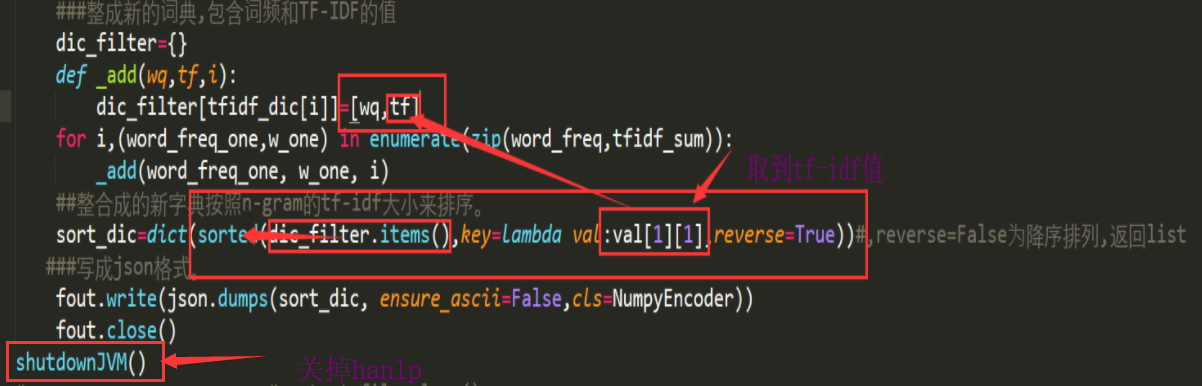
下面利用sklearn里的方法来计算tf-IDF,按照TF-IDF值排序,再整合成{词语:[词频,TF-IDF值]}的字典保存成json格式。


补充知识:
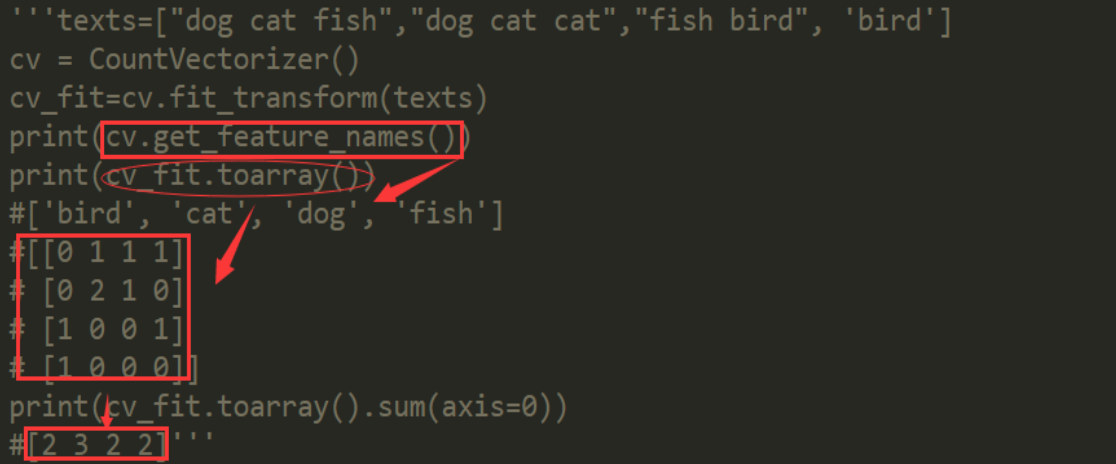
'''CountVectorizer+TfidfTransformer
CountVectorizer会将文本中的词语转换为词频矩阵,
它通过fit_transform函数计算各个词语出现的次数,通过get_feature_names()可获得所有文本的关键词,
通过toarray()可看到词频矩阵的结果。
TfidfTransformer用于统计vectorizer中每个词语的TFIDF值。
'''

计算词频,再计算TF-IDF的值: