在特定领域我们需要利用该模型构建自己的分词和词性标注,已有的分词工具或词性标注工具在通用领域可能会很好,但是在特定领域效果会很差。
前提假设:
前后的两个词是有联系的(也是HMM的假设前提),通过条件概率来计算句子的合理性。
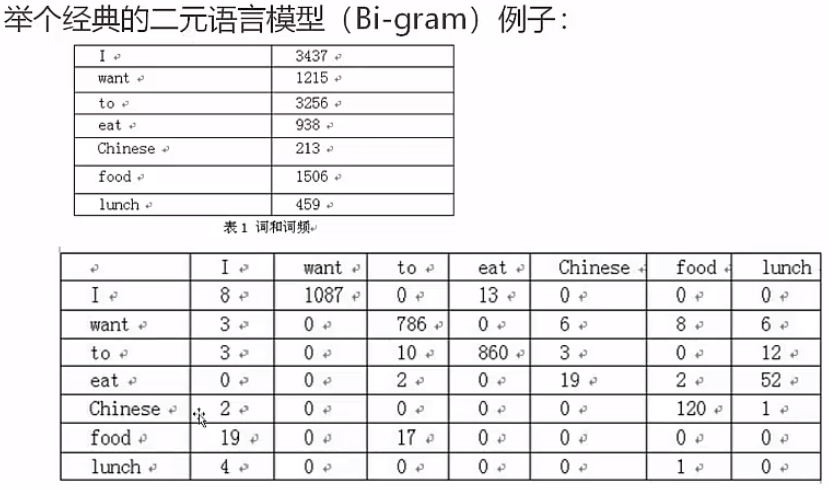
一张词频表(含有大量的文本——我们的语料库,在中文中我们需要分词再做词频统计),第二张表则是一个关键词共现矩阵和Bi-GRAM计算。Tri-GRAM相似。

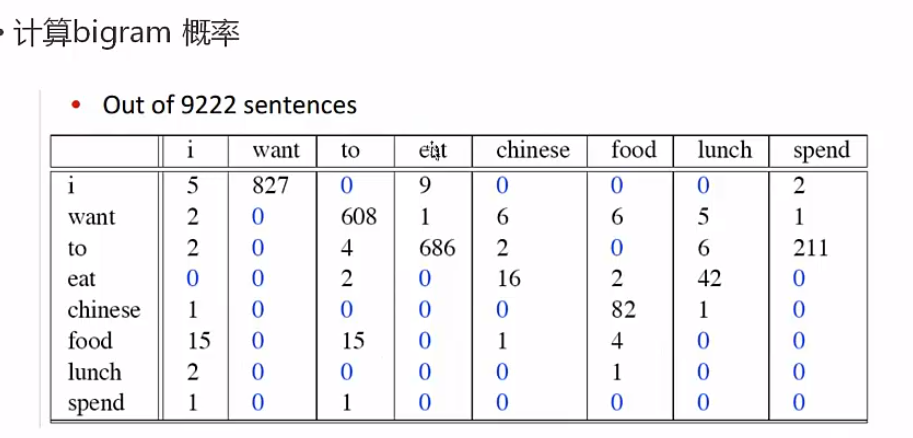
另一例子:

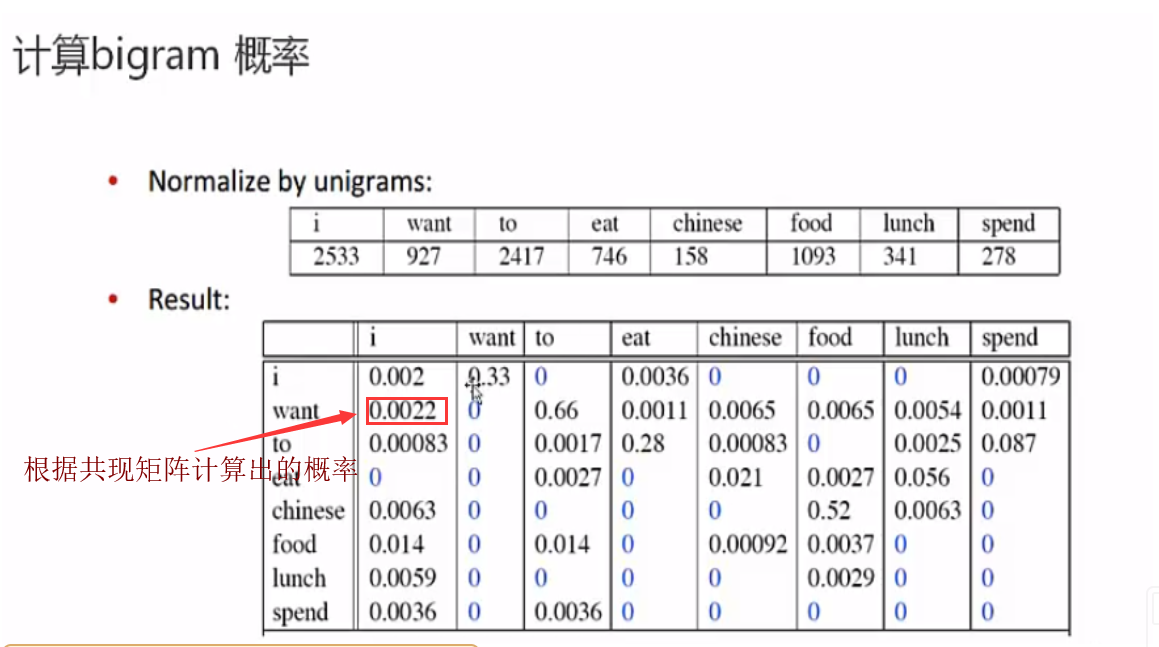
注:
基于N-gram还出现了更多有价值的语言模型,如NNLM、CBOW等。
在特定领域我们需要利用该模型构建自己的分词和词性标注,已有的分词工具或词性标注工具在通用领域可能会很好,但是在特定领域效果会很差。
前提假设:
前后的两个词是有联系的(也是HMM的假设前提),通过条件概率来计算句子的合理性。
一张词频表(含有大量的文本——我们的语料库,在中文中我们需要分词再做词频统计),第二张表则是一个关键词共现矩阵和Bi-GRAM计算。Tri-GRAM相似。
另一例子:
注:
基于N-gram还出现了更多有价值的语言模型,如NNLM、CBOW等。
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。