分词,分词的重要性不想多说,分词的方法也多种多样根据你的任务来选择适当的方法吧。
逆向最大匹配分词算法在我看来已经很老了,但是在学校学习老师还是会建议我们以任务的形式来再完成一遍,算是个自然语言处理的基础吧,能够帮助我们更好的理解什么是分词。
逆向最大匹配分词的原理:逆向向最大匹配分词需要在已有词典的基础上,从被处理文档的末端开始匹配扫描,每次取最末端的i个字符(分词所确定的阈值i)作为匹配字段,若匹配失败,则去掉匹配字段最前面的一个字,继续匹配。而且选择的阈值越大,分词越慢,但准确性越好。
优点:逆向最大匹配分词是中文分词基本算法之一,因为是机械切分,所以它也有分词速度快的优点,且逆向最大匹配分词比起正向最大匹配分词更符合人们的语言习惯。
首先要有两个词典:一个是我们文本对应领域的词典,一个是停用词词典。以及我们要分词的txt文本。

词表文件夹中的包含两个文件:![]() ,停用词典网上很多,可以自行查找。自己用的词典就需要自己去找和整理了,主要还是根据你的文本类型来。假如你是医学类的文本你可能需要自己去写爬虫从各类医学网站上去爬取再整理了。
,停用词典网上很多,可以自行查找。自己用的词典就需要自己去找和整理了,主要还是根据你的文本类型来。假如你是医学类的文本你可能需要自己去写爬虫从各类医学网站上去爬取再整理了。
下面直接上我在做任务时的代码:

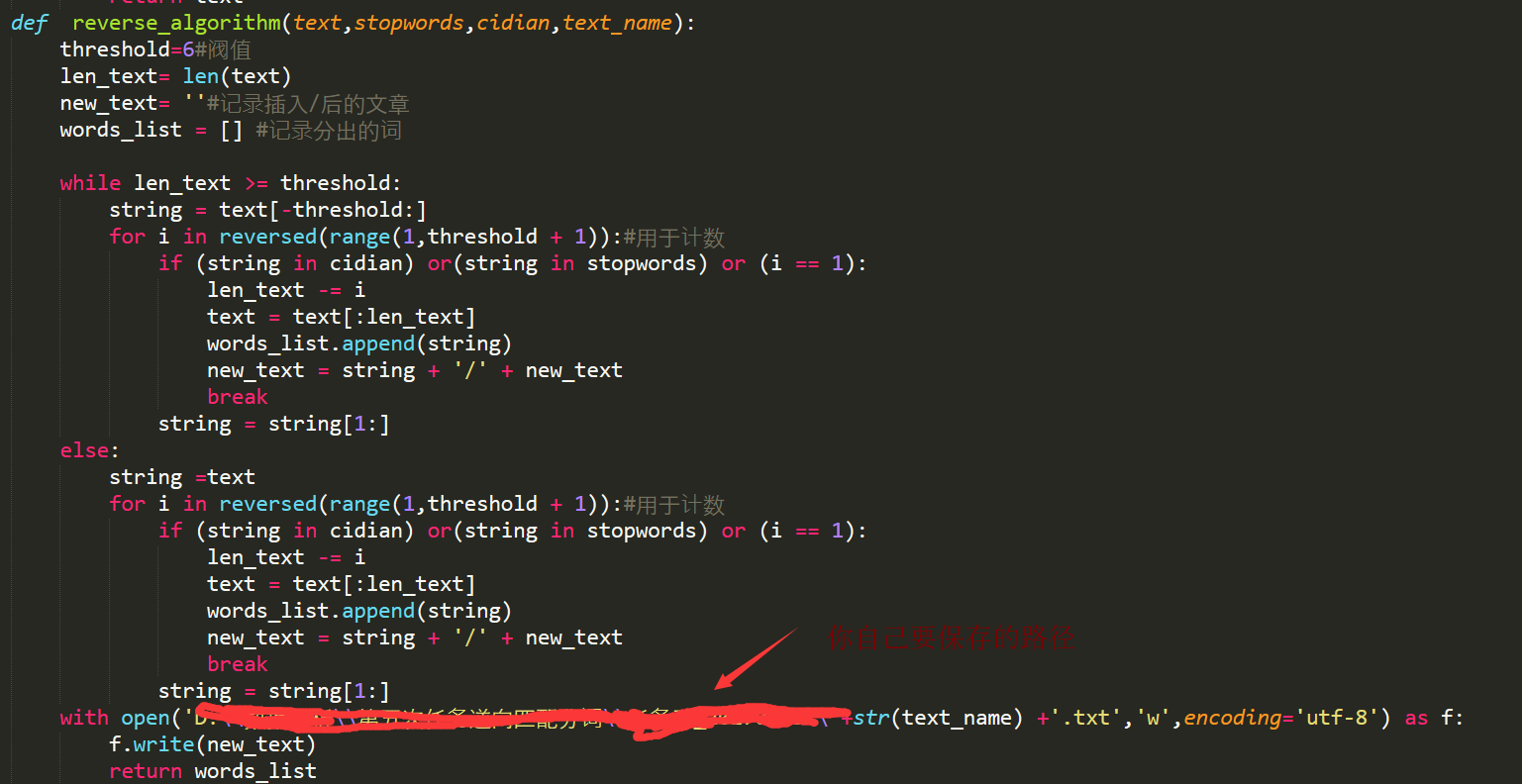

最后结果的样子:
