google根据中文的一部分数据已经为中文预训练了一个模型,bert-base-cased(12层,768,12头),之所以要预训练是为了针对领域的数据有更好的拟合能力。例如法律方面的数据。
预训练模型文件夹所包含的文件:用原始数据生成一句一行,隔行分段后,供130M数据,生成examples.tf_cored大概要1小时。后面用run_pretraining.py训练,大概10000步要一小时(设备信息:54G内存,16G显存。),根据设备性能,我选着的是句子256个长-(经过解析源码:预训练阶段max_seq_length应该是两个句子的长度。),batchsize:8,当然根据官网可以写16,但是8保险。
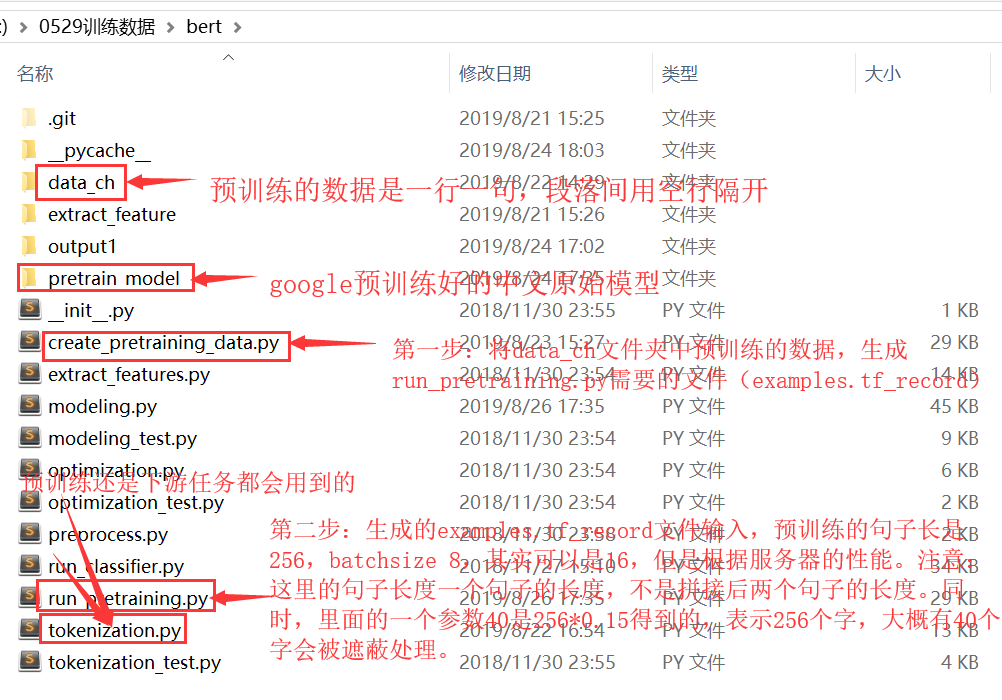

总结知识点:在寻训练阶段过程,(1)先将原始数据集整理成一行一句,空行分割不同文章。在bert预训练原始数据集的准备.py。(2),用create_pritrain_data.py生成预训练run_pretraining.py需要的examples.tf_record。(3)在run_pretraining.py文件中,40那个参数要小心,句子长256*0.15。
小知识点:bert预训练有两个任务,一、预测出遮蔽词,二,预测第二个句子是不是原来句子的正常第二句,是个【0,1】分类。
bert在训练中文模型时的学习率是10-4。在微调预训练时,学习率要调小,例如2E-5.