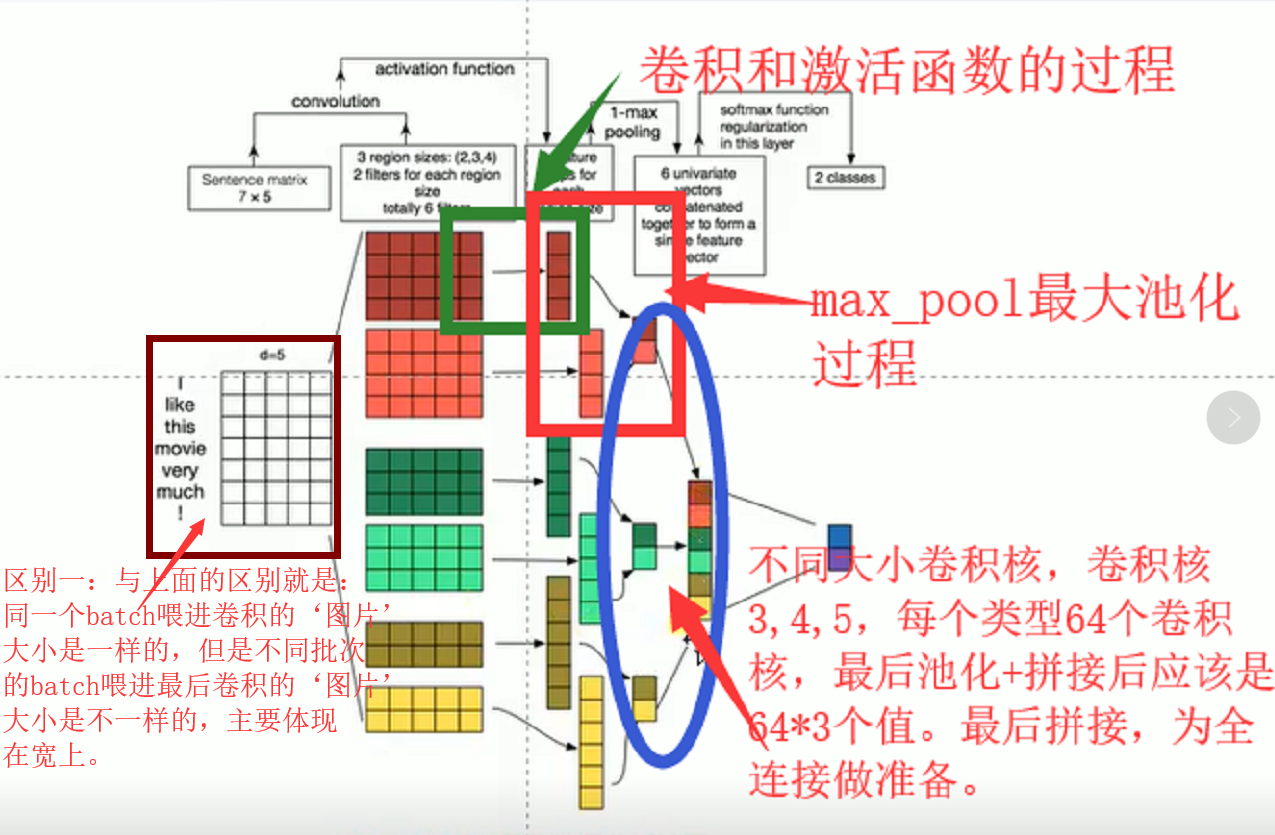
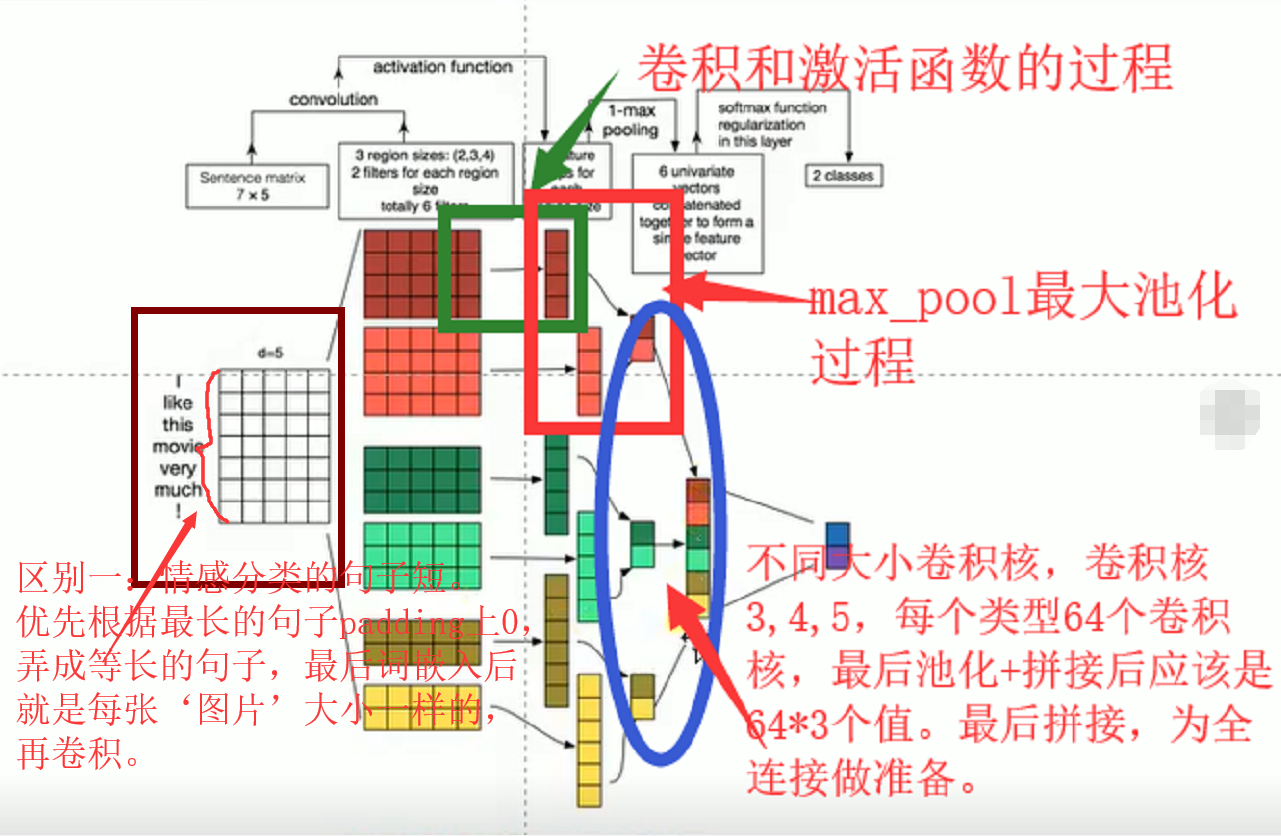
区别:
区别一:情感表达的句子相对较短,全部最长的句子也就56个词组成,因此在数据准备和特征提取时优先将每个不同长度的句子都统一padding 上0,在model中词嵌入后,结果类似长、宽都是一样的图片,进行卷积。主要用的事tf的learn来实现句子等长功能。
如图:每个batch喂进去的‘图片’都是一样大小。
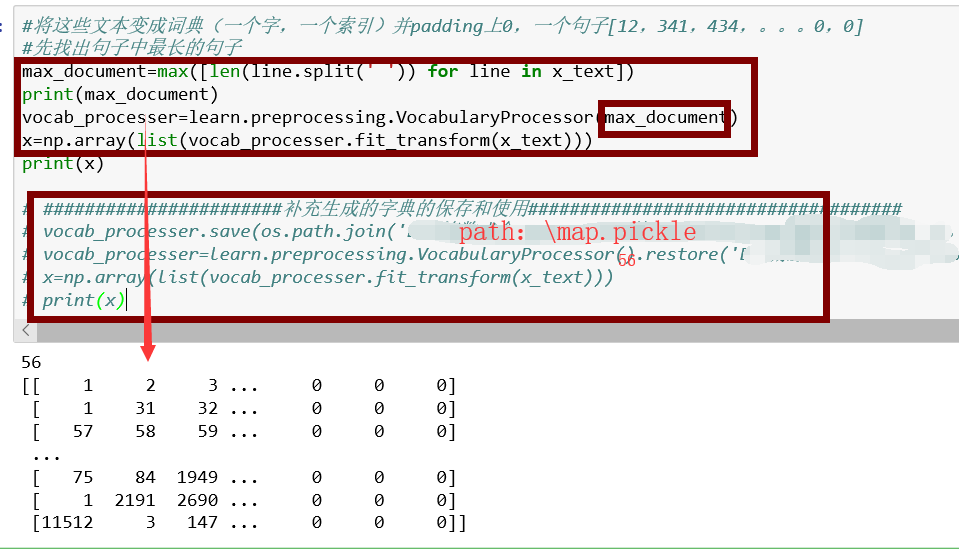
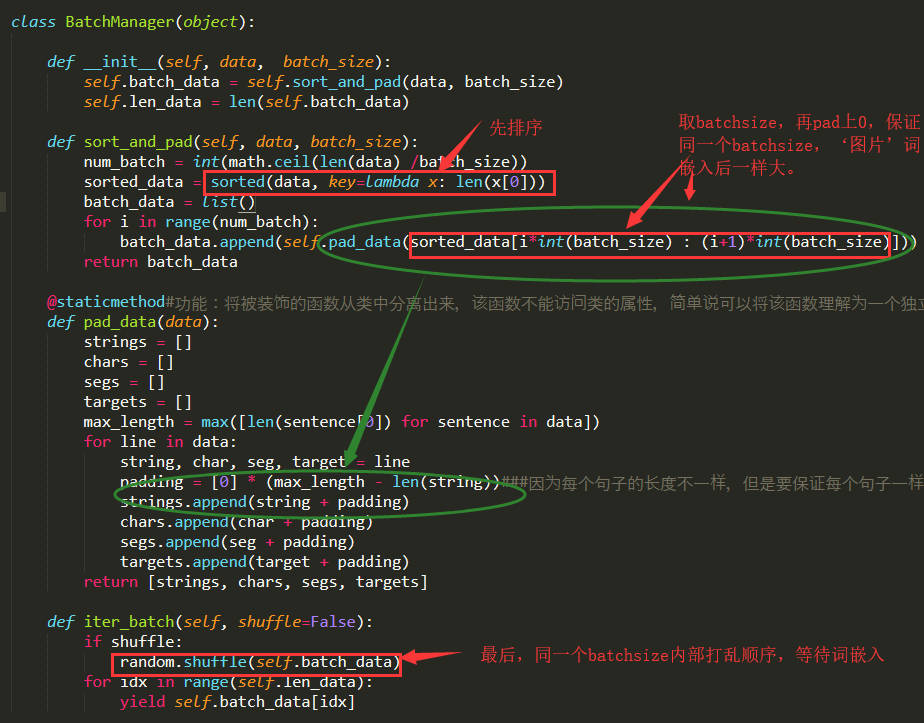
区别一:由于医疗文本是段落,长短不一,有的10几个字,有的高达400-500字。因此为了节约资源,选着在batch的时候进行padding上0,具体的做法是先对输入的所有的特征按一个文本中字的个数先排序,这样相对短长的文本就会排在前面,再取batchsize,比如batchsize=60,前60个相对较短的文本就会在前面,这时对这个取出的60个,padding上0。最后的结果在model中词嵌入后,结果类似每个batch之间,所有图片的长都是一样的,但是宽可能不一样,要根据每次取出来的那60文本中哪个最长,但是一定是越来越长的,因为我们先在前面对文本先排过序。(注:分类器不是softmax时才可以使用这种方法,softmax需要输入是等长的,这里用的最后接的事CRF)