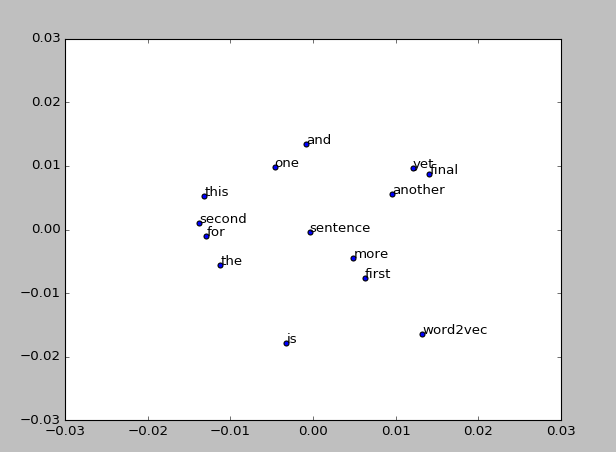
结果:
代码:
# -*- coding: utf-8 -*-
from gensim.models import Word2Vec
from sklearn.decomposition import PCA
from matplotlib import pyplot
# 训练的语料
sentences = [['this', 'is', 'the', 'first', 'sentence', 'for', 'word2vec'],
['this', 'is', 'the', 'second', 'sentence'],
['yet', 'another', 'sentence'],
['one', 'more', 'sentence'],
['and', 'the', 'final', 'sentence']]
# 利用语料训练模型
model = Word2Vec(sentences,window=5, min_count=1)
from gensim.models import Word2Vec
from sklearn.decomposition import PCA
from matplotlib import pyplot
# 训练的语料
sentences = [['this', 'is', 'the', 'first', 'sentence', 'for', 'word2vec'],
['this', 'is', 'the', 'second', 'sentence'],
['yet', 'another', 'sentence'],
['one', 'more', 'sentence'],
['and', 'the', 'final', 'sentence']]
# 利用语料训练模型
model = Word2Vec(sentences,window=5, min_count=1)
#添加vocab:
model.build_vocab(sentences, update=True) #添加vocab
model.build_vocab(sentences, update=True) #添加vocab
#check是否添加成功:
for k,v in model.wv.vocab.items():
print (k,v)
for k,v in model.wv.vocab.items():
print (k,v)
# 基于2d PCA拟合数据
X = model[model.wv.vocab]
pca = PCA(n_components=2)##PCA无监督的降维,LDA线性判别分析:有监督的降维
X = model[model.wv.vocab]
pca = PCA(n_components=2)##PCA无监督的降维,LDA线性判别分析:有监督的降维
result = pca.fit_transform(X)
print(result)
print(result[:, 0])
# 可视化展示
pyplot.scatter(result[:, 0], result[:, 1])##scatter:散开,分散,两个点
words = list(model.wv.vocab)
for i, word in enumerate(words):
pyplot.annotate(word, xy=(result[i, 0], result[i, 1]))##annotate:注释
pyplot.show()
print(result)
print(result[:, 0])
# 可视化展示
pyplot.scatter(result[:, 0], result[:, 1])##scatter:散开,分散,两个点
words = list(model.wv.vocab)
for i, word in enumerate(words):
pyplot.annotate(word, xy=(result[i, 0], result[i, 1]))##annotate:注释
pyplot.show()